Introduction
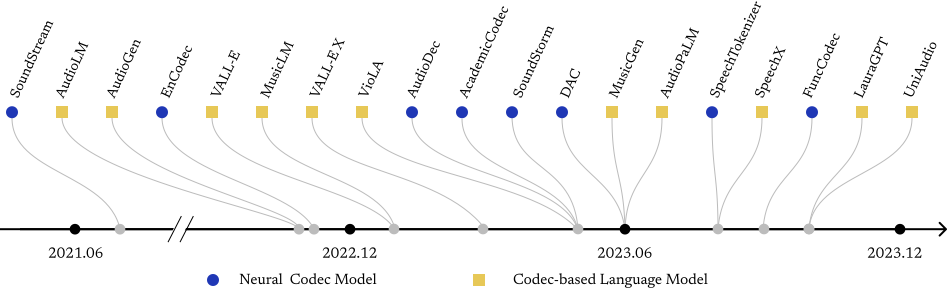
Neural audio codecs are initially introduced to compress audio data into compact codes to reduce transmission latency. Researchers recently discovered the potential of codecs as suitable tokenizers for converting continuous audio into discrete codes, which can be employed to develop audio language models (LMs). The neural audio codec's dual roles in minimizing data transmission latency and serving as tokenizers underscore its critical importance. The ideal neural audio codec models should preserve content, paralinguistics, speakers, and audio information. However, the question of which codec achieves optimal audio information preservation remains unanswered, as in different papers, models are evaluated on their selected experimental settings. There's a lack of a challenge to enable a fair comparison of all current existing codec models and stimulate the development of more advanced codecs. To fill this blank, we propose the Codec-SUPERB challenge.





